
To decentralise, or not to decentralise, that is the question. As well as echoing Shakespeare’s play Hamlet, this dilemma reflects the likely thoughts of current digital leaders who want to make the best use of their digital assets while maintaining trust in their data systems.
Increasing concerns about how personal data is being managed online has led to the emergence of decentralised platforms as an alternative for giving back control and transparency to the prime data owner. But the recent hype around decentralised technologies heralded as Web3, in which the future of the internet will be based on decentralised, quasi-anonymous platforms, is making it difficult for enterprises to clearly understand the value at stake in adopting such technology as part of their ambitious digital transformation strategy.
Time will tell whether Web3 technology platforms will live up to the expectations of being a viable alternative to established centralised (cloud) platforms in terms of user trust, value generation, scalability, privacy and security to name a few. In the meantime, digital and product leaders who understand the value of distributed data – but have not yet decided on which data architecture to adopt – face a difficult decision over which approach would be most suitable for their applications.
Redefining business with digital service innovation
Decentralised data architecture
In this article, I want to discuss the steps that data-driven enterprises should take when deciding whether a decentralised data architecture is the right path when addressing distributed data sharing, such as personal data, and if so what level of decentralisation would be required. I’ll explain the importance of specific use case definition as well as the key questions that a digital enterprise should answer before investing in their data platform architecture.
Let’s consider the many options available to the buyer of a brand new car. Products are often tailored to match specific buyer profile needs which can vary greatly. Similarly, there is not a market agnostic one-size-fits-all data architecture solution that could address every data challenge. So, establishing solid use cases should be one of the first steps towards creating a compelling data sharing strategy. A clear picture is needed that maps how a more effective data sharing infrastructure could be used to address the use-case-specific stakeholder needs and pain points.
The use cases must be well-defined, manageable and have a tangible business benefit. While stakeholder needs and pains will vary depending on the industry sector, most data sharing tensions will revolve around six main pillars – privacy, trust, utility, operation, permission/control, and regulations. To discover more about them and how they fit within the concept of decentralisation, as well as getting up to speed with the major decentralised platform technologies, do have a look at my colleague Martin Cookson’s thoughts on digital services.
While decentralised platforms in areas other than financial services are yet to be commercially proven, there are ongoing attempts to create pilot solutions for personal data storage in different market areas. For instance, the Greater Manchester Digital Platform (GMDP) programme in the UK has been testing a Personal Online Data Store (PODS) solution to provide a unified place for dementia patients to manage their health record data. The joint initiative is carried by multiple healthcare bodies in Manchester, as well as technology partners whose objective has been to address the current disconnect between patients and their healthcare data that is kept on different systems and places.
To address this gap, the platform uses the open-source tool Solid to provide decentralised user data storage in the form of PODS that is integrated with third party healthcare service provider systems. The use of Solid PODS has enabled the GMDP initiative to specifically address the challenge of distributed personal data by storing patient data in a decentralised way that gives patients control over their personal data sharing.
Another example of the intended use of decentralised storage is the recent publication from the BBC stating that the broadcaster has been working on building personal data store prototypes. The BBC’s specific use case revolves around addressing young audiences, who are not regular users of the corporation’s online products and services, and looking at aspects such as trust, relevance, and user experience.
Considering decentralised personal data storage as the next step to increase the value given to its audience, the BBC created multiple prototype solutions alongside a two-week qualitative research study. The key findings revealed that although there is a lack of user awareness on how to manage personal data, younger audiences are open to the concept of personal data stores and put high value on data visibility and control.
While the Solid PODS technology can address personal data storage and control, it might not be suitable for use cases with different requirements which could be addressed by alternative decentralised approaches. Wakam is an embedded insurance provider of custom white-label solutions that has adopted a DLT blockchain technology as part of its policy admin system. The use of blockchain, and more specifically smart contracts, has allowed the company to automate its complex claims management system leading to greater transparency of data transactions and addressing the challenge of trust.
These examples highlight the importance of defining the main use case challenges and ambitions before planning the technology proof-of-concept approach. At Cambridge Consultants, we have been assessing this relationship and exploring how decentralised platform technologies could drive the next digital transformation wave. More specifically, we have been looking into examples such as renewable energy to understand how ‘green’ energy data use in smart homes could be managed and shared securely and reliably using a decentralised platform solution. We reviewed a variety of potential technologies as part of a benchmarking and are in the process of developing a suitable architecture – stay tuned!
Picking the right data architecture
Once the distributed data challenges are known and the use cases are well defined, it is essential to choose the right technology architecture to meet those needs. I’ve summarised the key steps (Figure 1) that digitally driven enterprises should consider when deciding where their focus should go when building their data architecture.
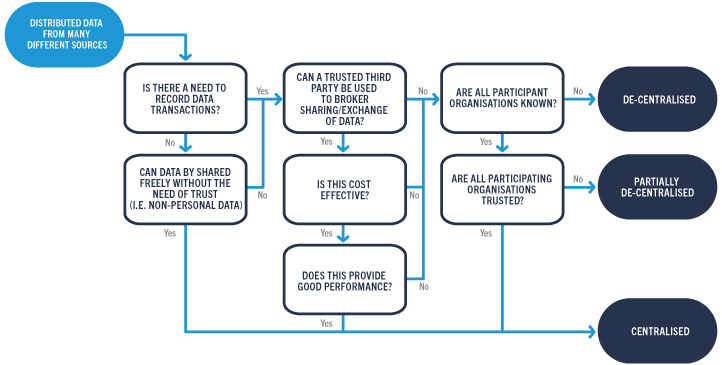
Figure 1, source: Cambridge Consultants, Department of Computer Science; ETH Zurich and Imperial College London
The flowchart is a simplified view of the assumptions required when choosing a specific data architecture. While some use cases might require additional assumptions compared to others, there is a degree of uniformity when it comes to distributed data sharing. That’s why we’ve developed a medical use case to provide more tangibility to this exercise.
In the example below, we have simulated a medical use case scenario like the GMDP initiative for patient data management. To clearly illustrate the process, we will look at the assumptions being made step-by-step:
- There is often a need for medical data – for example from electronic health records (EHRs) – to be captured and recorded. This might improve the quality of the service or build upon the patient record history
- A trusted third party is essential if the data is to be shared or exchanged between healthcare service providers
- In a healthcare use case, if data sharing or exchange is managed successfully, it could reduce compliance costs and/or optimise processes
- This often translates to better system performance leading to better patient outcomes, but further assumptions may be needed, such as system compatibility, participant organisations and so on, especially in a highly regulated sectors such as healthcare
- In a healthcare scenario, all participant organisations must be known
- Personal data is highly secure and confidential and there might be a need for greater data transparency. We are seeing a growing need for personal data control which provides an opportunity for a hybrid solution where some of the personal data is stored in a decentralised manner while still being shared in a centralised way (via brokering or a data exchange) with the necessary user consent
Worked example for medical use case
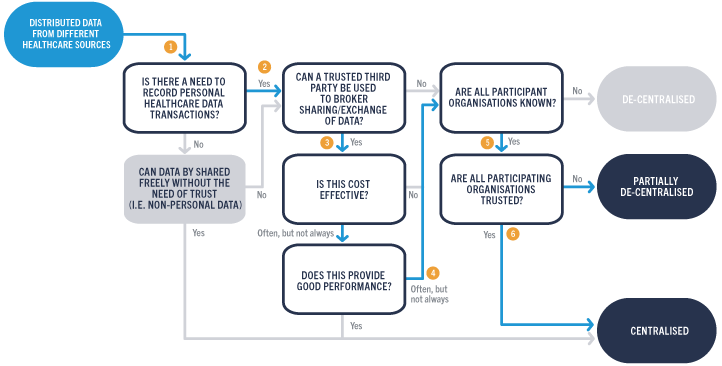
Figure 2
It’s important to start early
Currently, the lower barrier for entry and well-established data cloud business model enable a quicker scale-up for new entrants who want to capture value from distributed data as part of their use case(s). However, with the increasing user awareness on how personal data is being used without prior consent as well as the heightening concerns on transparency, security and privacy, decentralised architectures would become more prevalent and established.
Indeed, we have already seen successful decentralised examples and we are still at the development early stages. Digital leaders should not wait for this to unfold but rather plan for a more hybrid future where a potential symbiosis between centralised and decentralised architectures, and not the one or the other, would be the way forward. If you’d like to talk further on how you can meet your data challenges, please メール.
専門家

Ivan is a technology strategy consultant advising clients on how technology innovation could impact their business.


